@aaa,
With the example file, Good Tables finds it structurally valid, and looking at it manually that seems about right. I guess when they wrote CSVLint, they didn’t consider unicode support in their code, but in GoodTables, I did :). So - this is an issue with the implementation, not the file format itself.
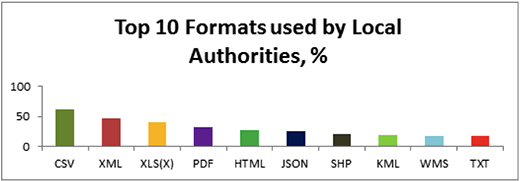
About Excel - to be totally clear, I have no problem with Excel whatsoever. I do not believe that it is right or reasonable to expect data to be produced outside of Excel in the vast majority of cases for many, many years to come. GoodTables actually supports all Excel formats in addition to CSV, but, as you may know, Excel is not exactly a walk in the park due to the date format and other quirks.
The point is though, that Excel, the program, reads and writes CSV - this is how spend data of UK ministries is produced, in Excel, and published as both Excel and CSV.
About formats, firmer foundations and so on. It is kind of like the arguments around Javascript in comparison to other programming languages: Let’s not let best be the enemy of good.
I think CSV to open data will basically for the foreseeable future be like Javascript for web programming: sure, it is not perfect, it is even weird sometimes, missing (supposedly) fundamental data types and so on - yet, it basically has the minimum you need to get stuff done, and a growing ecosystem to fill the gaps.

 converter (such as
converter (such as 